- жµПиІИ: 1125180 жђ°
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2012-01 ( 99)
- 2011-12 ( 145)
- 2011-11 ( 166)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
lyqf365пЉЪ
monoж≠їдЇЖ?monoзЪДеЉАеПСеЫҐйШЯдїОnovelеИЖз¶їеЗЇжЭ•еїЇзЂЛдЇЖдЄАдЄ™ ...
зФ±monoж≠їдЇЖжЙАжГ≥еИ∞зЪД -
kittychinaпЉЪ
дЄНйФЩпЉБ
2012жХ∞жНЃеЇУжЮґжЮДиІДеИТ -
иѓЄзДХиЊЙпЉЪ
[color=blue][/color]дљ†еЊИдЄНйФЩзЪДдЄАзѓЗжЦЗж°£
RBACжЭГйЩРиЃЊиЃ°еЃЮдЊЛ -
yangxing1002пЉЪ
ж≤ЩиИЯзЛЉеЃҐ еЖЩйБУUser_Java еЖЩйБУз•®жШѓж≠їзЪДгАВжЭГељУеХЖеУБдЇЖпЉМжФЊ ...
еѓєдЇО12306пЉМжИСзЪДеЃМжХіжКАжЬѓжЦєж°И -
MybeautifulпЉЪ
е¶ВжЮЬеП™жШѓеИЖи°®е∞±иГљиІ£еЖ≥зЪДйЧЃйҐШпЉМеНЪдЄїеПИжЮБе§ІзЪДиЧРиІЖдЇЖдЄЛ йУБиЈѓзЪДеФЃз•®з≥ї ...
йУБиЈѓзЪДеФЃз•®з≥їзїЯжЭ•иѓіжШОеИЖеЇУеИЖи°®еѓєжЮґжЮДзЪДељ±еУН
и°МеЉПжХ∞жНЃеЇУиѓДжµЛпЉЪOracle 11g R2дЉБдЄЪзЙИ
жЬђжЦЗжИСдїђе∞ЖиѓДжµЛдЉ†зїЯзЪДи°Ме≠ШеВ®жХ∞жНЃеЇУпЉМиѓДжµЛзЪДйЗНзВєдїНзДґжШѓtpc-hеИЖжЮРеЮЛжߕ胥пЉМдЄїи¶Бж£Ай™МеРДзІНжХ∞жНЃеЇУеЬ®жХ∞жНЃдїУеЇУжЦєйЭҐзЪДиГљеКЫгАВжИСдїђдїОеЄВеЬЇеН†жЬЙзОЗжЬАйЂШзЪДеХЖдЄЪжХ∞жНЃеЇУOracleеЉАеІЛгАВ
гААгААдЄАгАБжХ∞жНЃеЇУеЃЙи£Е
гААгААOracleеЬ®еЕґеЃШжЦєжКАжЬѓзљСзЂЩдЄКжПРдЊЫдЇЖOracle 10g R2гАБ11g R1гАБ11g R2з≠ЙеРДзІНзЙИжЬђиљѓдїґзЪДдЄЛиљљпЉМињЩйЗМдєЯжПРдЊЫдЇЖжЦЗж°£еЬ®зЇњжµПиІИеТМдЄЛиљљпЉМињЩдЄЇзФ®жИЈиѓХзФ®еЄ¶жЭ•дЇЖжЦєдЊњпЉМдљЖеАЉеЊЧдЄАжПРзЪДпЉМиЩљзДґиљѓдїґжЬђиЇЂж≤°жЬЙеѓєеКЯиГљеТМиѓХзФ®жЬЯйЩРињЫи°МйЩРеИґпЉМдљЖеЬ®зФ®жИЈеНПиЃЃдЄ≠еѓєзФ®жИЈзЪДжЭГеИ©еТМдєЙеК°жЬЙжШОз°ЃзЪДзЇ¶еЃЪпЉМзФ®жИЈењЕй°їжО•еПЧеНПиЃЃжЙНиГљиѓХзФ®гАВзФ±дЇОOracleеЈ≤зїПеЃ£еЄГOracle 10g R2гАБ11g R1дЇІеУБзФЯеСљеС®жЬЯзЪДзїУжЭЯжЧ•жЬЯпЉМж≠§еРОдЄНеЖНжПРдЊЫжКАжЬѓжФѓжМБжЬНеК°гАВйАЪињЗжЦЗж°£жИСдїђдЇЖиІ£еИ∞пЉМдЉБдЄЪзЙИжѓФж†ЗеЗЖзЙИеЕЈжЬЙжЫіе§ЪзЪДйЂШзЇІеКЯиГљпЉМжѓФе¶ВпЉЪеИЖеМЇгАБеєґи°Мжߕ胥з≠ЙпЉМдєЯеЕЈжЬЙжЫіе§ІзЪДжЙ©е±ХжАІгАВеЫ†ж≠§жИСдїђйЗЗзФ®11g R2дЉБдЄЪзЙИжЭ•еБЪиѓДжµЛпЉМдї•жЬАе§ІйЩРеЇ¶еЬ∞дЇЖиІ£ињЩдЄ™дЇІеУБзЪДеЕ®йГ®еКЯиГљгАВеЬ®дЄКињ∞зљСзЂЩж≥®еЖМдЄАдЄ™еЕНиієзФ®жИЈе∞±еПѓдї•дЄЛиљљеЃЙи£ЕжЦЗдїґгАВ
гААгААOracle 11.2жФѓжМБзЪДеє≥еП∞жЬЙwindows 32дљН/64дљНгАБlinuxгАБSolarisгАБHP-UX гАБAIXз≠Й10зІНгАВжЬђжђ°жµЛиѓХеЯЇдЇОIntel Xeon 7550*8зЪДPCжЬНеК°еЩ®дЄКзФ®VMWare VSphere 4.1зЃ°зРЖзЪДиЩЪжЛЯжЬЇпЉМиЩЪжЛЯжЬЇзЪДйАїиЊСCPUдЄ™жХ∞жШѓ8пЉМеЖЕе≠Ш100GBпЉМе≠ШеВ®дЄЇ8дЄ™300GB SASжЬђеЬ∞з£БзЫШпЉМйЗЗзФ®дЄАеЭЧ512MзЉУе≠ШRAIDеН°пЉМжМЙRAID5жЦєеЉПзїДжИРз£БзЫШйШµеИЧгАВжУНдљЬз≥їзїЯйЗЗзФ®еТМRHEL 5зЫЄеРМзЪДж†ЄењГзЇІеИЂзЪДRedFlag Asian Linux Sever 3.0 x64гАВеЫ†ж≠§йАЙзФ®зЪДеЃЙи£ЕжЦЗдїґжШѓ64дљНx86 LinuxзЙИжЬђпЉМlinux.x64_11gR2_database_1of2.zipеТМlinux.x64_11gR2_database_2of2.zipпЉМ2дЄ™жЦЗдїґеРИиЃ°е§ІзЇ¶2.2G,ењЕй°їйГљдЄЛиљљпЉМзДґеРОиІ£еОЛзЉ©еИ∞еРМдЄАдЄ™зЫЃељХжЙНиГљжЙІи°МеЃЙи£ЕгАВOracleзЪДеЃЙи£ЕеЬ®еРДзІНжХ∞жНЃеЇУељУдЄ≠зЃЧжШѓжѓФиЊГе§НжЭВзЪДпЉМдљЖзФ±дЇОOracleзЪДеЄВеЬЇеЬ∞дљНеТМжµБи°Мз®ЛеЇ¶пЉМдЄУйЧ®дїЛзїНеЃЙи£ЕзЪДжЦЗж°£еЬ®дЇТиБФзљСдЄКдєЯжШѓдЄНиЃ°еЕґжХ∞гАВеЫ†ж≠§жЬђжЦЗдЄНеЗЖе§Зиѓ¶зїЖдїЛзїНжѓПдЄ™ж≠•й™§пЉМеП™иѓіжШОдЄАдЇЫеИЭжђ°дљњзФ®иАЕжШУйФЩзЪДеЕ≥йФЃж≠•й™§гАВжЫіиѓ¶зїЖзЪДж≠•й™§пЉМеПВиАГеЃШжЦєеЃЙи£ЕжЦЗж°£гАВ
гААгААеЬ®LinuxзОѓеҐГињЫи°МOracleеЃЙи£ЕзЪДеЕ≥йФЃж≠•й™§жЬЙдЄЛйЭҐеЗ†ж≠•пЉЪ
гААгАА1гАБеЕИеЖ≥жЭ°дїґж£АжЯ•пЉМж£АжЯ•еЖЕе≠ШгАБдЇ§жНҐжЦЗдїґеТМдЄіжЧґжЦЗдїґзЫЃељХе§Іе∞Пдї•еПКжУНдљЬз≥їзїЯзЙИжЬђжШѓеР¶зђ¶еРИOracleеЃЙи£ЕзЪДжЬАдљОи¶Бж±ВгАВ
 [root@redflag11012501
~]# grep MemTotal/proc/meminfoMemTotal:103140528kB[root@redflag11012501
~]# grep SwapTotal/proc/meminfoSwapTotal:5996536kB[root@redflag11012501
~]# free
total used free sharedbuffers cachedMem:10314052857586969738183201389365261496-/+buffers/cache:358264102782264Swap:599653605996536[root@redflag11012501
~]# df-h/dev/shm/жЦЗдїґз≥їзїЯеЃєйЗПеЈ≤зФ®
еПѓзФ® еЈ≤зФ®% жМВиљљзВєtmpfs50G0
50G0%/dev/shm[root@redflag11012501
~]# uname-mx86_64[root@redflag11012501
~]# df-h/tmpжЦЗдїґз≥їзїЯеЃєйЗПеЈ≤зФ®
еПѓзФ® еЈ≤зФ®% жМВиљљзВє/dev/mapper/VolGroup00-LogVol00
24G5.4G 17G25%/[root@redflag11012501
~]# df-hжЦЗдїґз≥їзїЯеЃєйЗПеЈ≤зФ®
еПѓзФ® еЈ≤зФ®% жМВиљљзВє/dev/mapper/VolGroup00-LogVol00
24G5.4G 17G25%//dev/sda199M
13M 82M14%/boottmpfs50G0
50G0%/dev/shm/dev/mapper/vg0-datalv739G4.9G696G1%/user1[root@redflag11012501
~]# cat/proc/versionLinux
version2.6.18-194.1.AXS3
(packager@asianux.com) (gcc version4.1.220080704(Asianux3.04.1.2-48))
#1SMP Fri May710:03:53CST2010[root@redflag11012501
~]# uname-r2.6.18-194.1.AXS3
[root@redflag11012501
~]# grep MemTotal/proc/meminfoMemTotal:103140528kB[root@redflag11012501
~]# grep SwapTotal/proc/meminfoSwapTotal:5996536kB[root@redflag11012501
~]# free
total used free sharedbuffers cachedMem:10314052857586969738183201389365261496-/+buffers/cache:358264102782264Swap:599653605996536[root@redflag11012501
~]# df-h/dev/shm/жЦЗдїґз≥їзїЯеЃєйЗПеЈ≤зФ®
еПѓзФ® еЈ≤зФ®% жМВиљљзВєtmpfs50G0
50G0%/dev/shm[root@redflag11012501
~]# uname-mx86_64[root@redflag11012501
~]# df-h/tmpжЦЗдїґз≥їзїЯеЃєйЗПеЈ≤зФ®
еПѓзФ® еЈ≤зФ®% жМВиљљзВє/dev/mapper/VolGroup00-LogVol00
24G5.4G 17G25%/[root@redflag11012501
~]# df-hжЦЗдїґз≥їзїЯеЃєйЗПеЈ≤зФ®
еПѓзФ® еЈ≤зФ®% жМВиљљзВє/dev/mapper/VolGroup00-LogVol00
24G5.4G 17G25%//dev/sda199M
13M 82M14%/boottmpfs50G0
50G0%/dev/shm/dev/mapper/vg0-datalv739G4.9G696G1%/user1[root@redflag11012501
~]# cat/proc/versionLinux
version2.6.18-194.1.AXS3
(packager@asianux.com) (gcc version4.1.220080704(Asianux3.04.1.2-48))
#1SMP Fri May710:03:53CST2010[root@redflag11012501
~]# uname-r2.6.18-194.1.AXS3
гААгАА2гАБеИЫеїЇжУНдљЬз≥їзїЯoracleзФ®жИЈеТМзїДгАВеєґзїЩoracleзФ®жИЈиЃЊзљЃеП£дї§гАВ
[root@redflag11012501
~]#/usr/sbin/groupadd oinstall[root@redflag11012501
~]#/usr/sbin/groupadd-g502dba[root@redflag11012501
~]#/usr/sbin/groupadd-g503oper[root@redflag11012501
~]#/usr/sbin/groupadd-g504asmadmin[root@redflag11012501
~]#/usr/sbin/groupadd-g506asmdba[root@redflag11012501
~]#/usr/sbin/groupadd-g505asmoper[root@redflag11012501
~]#/usr/sbin/useradd-u502-g
oinstall-G dba,asmdba,oper oracle[root@redflag11012501
~]# passwd oracleChanging
passwordforuser oracle.NewUNIX
password:BAD
PASSWORD: itisbasedona dictionary wordRetypenewUNIX
password:passwd:
all authentication tokens updated successfully.
гААгАА3гАБиЃЊеЃЪoracleзФ®жИЈзЪДиµДжЇРйЩРеИґгАВSи°®з§ЇиљѓйЩРеИґгАБHи°®з§Їз°ђйЩРеИґгАВ
[root@redflag11012501
~]# su-oracle[oracle@redflag11012501
~]$ ulimit-Sn2048[oracle@redflag11012501
~]$ ulimit-Hn65536[oracle@redflag11012501
~]$ ulimit-Su16384[oracle@redflag11012501
~]$ ulimit-Hu16384[oracle@redflag11012501
~]$ ulimit-Ss10240[oracle@redflag11012501
~]$ ulimit-Hs unlimited
гААгАА4гАБзФ®rootзФ®жИЈиЃЊеЃЪз≥їзїЯж†ЄењГеПВжХ∞гАВдїО11.2еЉАеІЛпЉМOracleеЃЙи£ЕжЦЗдїґжПРдЊЫдЇЖиЗ™еК®дњЃжФєжЯРдЇЫеПВжХ∞зЪДеКЯиГљпЉМеЫ†ж≠§ињЩдЄАж≠•еПШеЊЧеПѓйАЙгАВеПѓдї•жЯ•зЬЛеОЯеІЛеПВжХ∞зЪДеАЉгАВ
[root@redflag11012501
~]#/sbin/sysctl-a | grep semkernel.sem=25632000100142[root@redflag11012501
~]#/sbin/sysctl-a | grep shmvm.hugetlb_shm_group=0kernel.shmmni=4096kernel.shmall=4294967296kernel.shmmax=68719476736[root@redflag11012501
~]#/sbin/sysctl-a | grep file-maxfs.file-max=131072
гААгАА5гАБеИЫеїЇеЃЙи£ЕдЇМињЫеИґжЦЗдїґе≠ШжФЊзЫЃељХеТМжХ∞жНЃеЇУжЦЗдїґе≠ШжФЊзЫЃељХз≠ЙпЉМеєґжФєеПШе±ЮдЄїдЄЇoracleгАВ
[root@redflag11012501
~]# mkdir-p/user1/app/oracle[root@redflag11012501
~]# chown-R oracle:oinstall/user1/app/oracle[root@redflag11012501
~]# chmod-R775/user1/app/oracle[root@redflag11012501
~]# mkdir-p/user1/app/oradata[root@redflag11012501
~]# chown-R oracle:oinstall/user1/app/oradata[root@redflag11012501
~]# chmod-R775/user1/app/oradata[root@redflag11012501
~]# mkdir-p/user1/app/recovery_area[root@redflag11012501
~]# chown-R oracle:oinstall/user1/app/recovery_area[root@redflag11012501
~]# chmod-R775/user1/app/recovery_area
гААгАА6гАБзФ®xеی嚥зХМйЭҐеЈ•еЕЈзЩїељХгАВеЬ®еی嚥зїИзЂѓдЄ≠жЯ•зЬЛdisplayзЪДзЂѓеП£пЉМеєґжНЃж≠§иЃЊеЃЪoracleзФ®жИЈDISPLAYзОѓеҐГеПШйЗПпЉМињРи°МеЃЙи£Ез®ЛеЇПrunInstaller,жМЙзХМйЭҐжПРз§ЇжУНдљЬгАВ
[root@redflag11012501
~]# xdpyinfoname
of display:10.4.105.241:1.0version
number:11.0vendorstring:NetSarang
Computer, Inc.vendor
release number:1391...[root@redflag11012501
~]#[root@redflag11012501
~]# su-oracle[oracle@redflag11012501
~]$ export DISPLAY=10.4.105.241:1.0[oracle@redflag11012501
~]$ cd/user1/app/oradata/database[oracle@redflag11012501
database]$ ./runInstaller
гААгАА7гАБеЃЙи£Ез®ЛеЇПж£АжЯ•еРОиЗ™еК®зФЯжИРдЇЖдњЃжФєж†ЄењГеПВжХ∞зЪДиДЪжЬђпЉМйЬАи¶БзФ®rootзФ®жИЈжЙІи°МгАВ
[root@redflag11012501
~]#/tmp/CVU_11.2.0.2.0_oracle/runfixup.sh/usr/bin/idResponse
file being usedis:/tmp/CVU_11.2.0.2.0_oracle/fixup.responseEnable
file being usedis:/tmp/CVU_11.2.0.2.0_oracle/fixup.enableLogfile
location:/tmp/CVU_11.2.0.2.0_oracle/orarun.logSetting
Kernel Parameters...fs.file-max=131072fs.file-max=6815744net.ipv4.ip_local_port_range=900065500net.core.rmem_max=262144net.core.rmem_max=4194304net.core.wmem_max=262144net.core.wmem_max=1048576fs.aio-max-nr=1048576
гААгААеЃЙи£Еж≥®жДПдЇЛй°єпЉЪ
гААгААOracleзФ®дЄАдЄ™еЃЙи£ЕеМЕеМЕжЛђдЇЖж†ЗеЗЖзЙИеТМдЉБдЄЪзЙИзЪДеКЯиГљпЉМеП™и¶БеЬ®еЃЙи£Ез±їеЮЛйАЙжЛ©дЉБдЄЪзЙИеН≥еПѓгАВ
гААгААеЃЙи£ЕеЃМжХ∞жНЃеЇУиљѓдїґеРОпЉМжЙІи°МdbcaеИЫеїЇжХ∞жНЃеЇУпЉМж≥®жДПйАЙжЛ©з±їеЮЛдЄЇдЄАиИђзФ®йАФпЉМSGAдЄАиИђзФ®йїШиЃ§зЪДзЙ©зРЖеЖЕе≠ШзЪД40%еН≥еПѓ,дЄНењЕиЃЊеЊЧињЗе§ІпЉМеЫ†дЄЇжУНдљЬз≥їзїЯйЬАи¶БйГ®еИЖеЖЕе≠ШдљЬжЦЗдїґзЉУе≠ШпЉМе¶ВжЮЬOracleеН†зФ®ињЗе§ІпЉМе∞±дЉЪељ±еУНжУНдљЬз≥їзїЯзЪДжУНдљЬпЉМдЄНдљЖдЄНиГљжПРйЂШжАІиГљпЉМеПНиАМдЉЪйЩНдљОжАІиГљгАВзФ®netcaеИЫеїЇзЫСеРђеТМжЬНеК°гАВе∞±еПѓдї•ињЫи°МдЄАиИђзЪДжµЛиѓХдЇЖгАВ
гААгААдЇМгАБTPC-HеЯЇеЗЖжµЛиѓХдїЛзїН
гААгАА1гАБиГМжЩѓ
гААгААTPCеН≥зЊОеЫљдЇЛеК°е§ДзРЖжХИиГљеІФеСШдЉЪ(Transaction Processing Performance Council)пЉМжШѓдЄАеЃґйЭЮзЫИеИ©жЬЇжЮДпЉМдєЯжШѓеЫљйЩЕдЄКжЬАеЕЈжЭГе®БжАІзЪДйЂШзЂѓиЃ°зЃЧеЩ®дЇІеУБжХИиГљиѓДжµЛзїДзїЗдєЛдЄАпЉМ襀зІ∞дЄЇ вАЬйЂШзЂѓиЃ°зЃЧжЬЇдЇІеУБзЂЮжКАзЪДеЫљйЩЕдњ±дєРйГ®вАЭгАВзЫЃеЙНеЬ®еЫљйЩЕдЄКеЗ†дєОжЙАжЬЙ ITзХМзЯ•еРНеОВеХЖйГљжШѓеЕґдЉЪеСШгАВиіЯиі£еЃЪдєЙдЇЛеК°е§ДзРЖдЄОжХ∞жНЃеЇУжАІиГљеЯЇеЗЖжµЛиѓХпЉМеєґдЊЭжНЃињЩдЇЫеЯЇеЗЖжµЛиѓХй°єзЫЃеПСеЄГеЃҐиІВжАІиГљжХ∞жНЃгАВTPCеЯЇеЗЖжµЛиѓХжЬЙжЮБдЄЇдЄ•ж†ЉзЪДињРи°Ми¶Бж±ВпЉМеєґдЄФеЬ®зЛђзЂЛеЃ°иЃ°жЬЇжЮДзЫСзЭ£дЄЛињЫи°МгАВ
гААгААTPC-H(еХЖдЄЪжЩЇиГљиЃ°зЃЧжµЛиѓХ)жШѓTPCзЪДйЗНи¶БжµЛиѓХж†ЗеЗЖдєЛдЄАпЉМдЄїи¶БзФ®жЭ•ж®°жЛЯзЬЯеЃЮеХЖдЄЪзЪДеЇФзФ®зОѓеҐГгАВеХЖдЄЪжЩЇиГљиЃ°зЃЧжµЛиѓХжШѓеѓєзО∞еЃЮдЄ≠еХЖзФ®иЃ°зЃЧйЬАж±ВзЪДеЕ®йЭҐж®°жЛЯгАВеЃГеМЕжЛђж®°жЛЯзЬЯеЃЮеХЖдЄЪдЇ§жШУжХ∞жНЃеЇУзЪДеК®жАБжߕ胥пЉМдї•еПКдљЬдЄЇеЖ≥з≠ЦжФѓжМБдЄОжХ∞жНЃеЇУеЇФзФ®з≥їзїЯзЪДеПВиАГгАВеПѓдї•еЕ®жЦєдљНиѓДжµЛз≥їзїЯзЪДжХідљУеХЖдЄЪиЃ°зЃЧзїЉеРИиГљеКЫпЉМеѓєеОВеХЖзЪДи¶Бж±ВжЫійЂШпЉМеРМжЧґдєЯеЕЈжЬЙжЩЃйБНзЪДеХЖдЄЪеЃЮзФ®жДПдєЙгАВ
гААгААTPC-H еЯЇеЗЖжµЛиѓХжШѓзФ± TPC-DеПСе±ХиАМжЭ•зЪДгАВTPC-H зФ® 3NF еЃЮзО∞дЇЖдЄАдЄ™жХ∞жНЃдїУеЇУ,еЕ±еМЕеРЂ 8 дЄ™еЯЇжЬђеЕ≥з≥ї/и°®,еЕґдЄ≠и°®REGIONеТМи°®NATIONзЪДиЃ∞ељХжХ∞жШѓеЫЇеЃЪзЪД(еИЖеИЂдЄЇ5еТМ25)пЉМеЕґеЃГ6дЄ™и°®зЪДиЃ∞ељХжХ∞пЉМеИЩйЪПжЙАиЃЊеЃЪзЪДеПВжХ∞SFиАМжЬЙжЙАдЄНеРМпЉМеЕґжХ∞жНЃйЗПеПѓдї•иЃЊеЃЪдїО 1GBпљЮ3TB дЄНз≠ЙгАВжЬЙ8дЄ™зЇІеИЂдЊЫзФ®жИЈйАЙжЛ©гАВжµЛиѓХжЧґпЉМе∞Ж22дЄ™е§НжЭВжߕ胥(SELECT)йЪПжЬЇзїДжИРжߕ胥жµБпЉМ2дЄ™жЫіжЦ∞(еЄ¶жЬЙINSERTеТМDELETEзЪДз®ЛеЇПжЃµ)жУНдљЬзїДжИРдЄАдЄ™жЫіжЦ∞жµБпЉМжߕ胥жµБеТМжЫіжЦ∞жµБеєґеПСжЙІи°МжХ∞жНЃеЇУиЃњйЧЃпЉМжߕ胥жµБжХ∞зЫЃйЪПжХ∞жНЃйЗПеҐЮеК†иАМеҐЮеК†гАВTPC-H еЯЇеЗЖжµЛиѓХеМЕжЛђ 22 дЄ™жߕ胥(Q1~Q22),еЕґдЄїи¶БиѓДдїЈжМЗж†ЗжШѓеРДдЄ™жߕ胥зЪДеУНеЇФжЧґйЧі,еН≥дїОжПРдЇ§жߕ胥еИ∞зїУжЮЬињФеЫЮжЙАйЬАжЧґйЧі.TPC-H еЯЇеЗЖжµЛиѓХзЪДеЇ¶йЗПеНХдљНжШѓжѓПе∞ПжЧґжЙІи°МзЪДжߕ胥жХ∞( QphH@size)пЉМеЕґдЄ≠ H и°®з§ЇжѓПе∞ПжЧґз≥їзїЯжЙІи°Ме§НжЭВжߕ胥зЪДеє≥еЭЗжђ°жХ∞пЉМsize и°®з§ЇжХ∞жНЃеЇУиІДж®°зЪДе§Іе∞П,еЃГиГље§ЯеПНжШ†еЗЇз≥їзїЯеЬ®е§ДзРЖжߕ胥жЧґзЪДиГљеКЫ.TPC-H жШѓж†єжНЃзЬЯеЃЮзЪДзФЯдЇІињРи°МзОѓеҐГжЭ•еїЇж®°зЪД,ињЩдљњеЊЧеЃГеПѓдї•иѓДдЉ∞дЄАдЇЫеЕґдїЦжµЛиѓХжЙАдЄНиГљиѓДдЉ∞зЪДеЕ≥йФЃжАІиГљеПВжХ∞пЉМжї°иґ≥дЇЖжХ∞жНЃдїУеЇУйҐЖеЯЯзЪДжµЛиѓХйЬАж±ВгАВ
гААгААеЬ®жИСдїђзЪДеЃЮй™МдЄ≠пЉМдЄЇдЇЖзЃАеМЦжУНдљЬпЉМеП™жµЛиѓХжߕ胥пЉМеєґиЃЊеЃЪзЪДSFзЪДеАЉдЄЇ10гАВи°®з§ЇжХ∞жНЃйЗПдЄЇ10GBзЇІеИЂгАВ8еЉ†и°®зЪДE/RеЫЊ(жЭ•иЗ™tpcеЃШжЦєжЦЗж°£)е¶ВдЄЛпЉЪ

гААгААйЬАи¶БиѓіжШОзЪДжШѓпЉМиЩљзДґжѓПдЄ™и°®йГљжЬЙеФѓдЄАйФЃ,и°®дєЛйЧіжЬЙеЉХзФ®еЕ≥з≥їпЉМTPC-HеєґдЄНи¶Бж±ВжµЛиѓХи°®еЃЪдєЙдЄ≠ењЕй°їеМЕеРЂдЄїйФЃеТМе§ЦйФЃеЃЪдєЙгАВиАМеЕБиЃЄжµЛиѓХзЪДжХ∞жНЃеЇУиЗ™и°МеЖ≥еЃЪгАВ
гААгААTPC-HзФ®жЭ•жЙІи°МзЪДжߕ胥еЕЈжЬЙдЄЛеИЧзЙєеЊБпЉЪ
гААгАА1гАБеЕЈжЬЙйЂШеЇ¶е§НжЭВжАІпЉЫ2гАБдљњзФ®еРДзІНиЃњйЧЃпЉЫ3гАБжШѓзЙєеЃЪзЪДпЉЫ4гАБж£АжЯ•еПѓзФ®жХ∞жНЃзЪДе§Іе§ЪжХ∞пЉЫ5гАБеРДдЄНзЫЄеРМпЉЫ6гАБжѓПжђ°жߕ胥зЪДеПВжХ∞еПѓеПШгАВ
гААгААињЩдЇЫжߕ胥䪯дЄЛеИЧеХЖдЄЪеИЖжЮРжПРдЊЫдЇЖз≠Фж°ИпЉЪ
гААгААдїЈж†ЉеТМжО®еєњгАБдЊЫеЇФеТМйЬАж±ВзЃ°зРЖгАБеȩ洶еТМжФґеЕ•зЃ°зРЖгАБй°ЊеЃҐжї°жДПеЇ¶з†Фз©ґгАБеЄВеЬЇдїљйҐЭз†Фз©ґгАБеПСиіІзЃ°зРЖгАВ
гААгААеЫ†ж≠§TPC-HзЪД22дЄ™жߕ胥洵зЫЦдЇЖеХЖдЄЪеИЖжЮРзЪДиѓЄжЦєйЭҐпЉМеЕЈжЬЙжЩЃйБНжАІеТМеЃЮзФ®жАІгАВдїОжߕ胥SQLиѓ≠еП•зЪДеЃЮйЩЕеЖЕеЃєжЭ•зЬЛпЉМеМЕжЛђзђ¶еРИSQL 92ж†ЗеЗЖзЪДи°®ињЮжО•гАБе≠Ржߕ胥пЉМINгАБEXISTSжУНдљЬпЉМHAVINGжУНдљЬпЉМGROUP BY,UNION,жЧ•жЬЯжУНдљЬпЉМдєЯжШѓеЕ®йЭҐеЬ∞ж£Ай™МдЇЖжХ∞жНЃеЇУеЇФдїШеРДзІНиѓ≠еП•зЪДиГљеКЫгАВ
гААгААж≥®жДПпЉЪеЕЈдљУжߕ胥sqlиѓ≠еП•ењЕй°їйАЪињЗdbgenеЈ•еЕЈдЇІзФЯпЉМйЩ§дЇЖйЩРеЃЪиЊУеЗЇиЃ∞ељХи°МжХ∞зЪДе≠РеП•пЉМдЄНеЕБиЃЄдЇЇеЈ•дњЃжФєеЖЩж≥ХгАВ
гААгАА2гАБжµЛиѓХжХ∞жНЃеТМжߕ胥иѓ≠еП•зЪДдЇІзФЯж≠•й™§
гААгААе∞ЖдїОtpcзљСзЂЩдЄЛиљљзЪДжЇРдї£з†БеМЕиІ£еОЛзЉ©пЉМдїОж®°жЭње§НеИґдЄАдїљmakefile,зДґеРОдњЃжФєеЕґдЄ≠еТМжХ∞жНЃеЇУз±їеЮЛгАБжУНдљЬз≥їзїЯз±їеЮЛзЫЄеЕ≥зЪДеЖЕеЃєпЉМжЙІи°МmakeзЉЦиѓСгАВ
[root@redflag11012501
tmp]# su-oracle[oracle@redflag11012501
~]$ cd/user1/app/oradata/tmp[oracle@redflag11012501
tmp]$ unzip/user1/app/tpch_2_13_0.zipArchive:/user1/app/tpch_2_13_0.zipinflating:
build.cinflating:
driver.cinflating:
bm_utils.cinflating:rnd.cinflating:
print.cinflating:
load_stub.cinflating:
bcd2.cinflating:
speed_seed.cinflating:
text.c....[oracle@redflag11012501
tmp]$ cp makefile.suite makefile[oracle@redflag11012501
tmp]$ vi makefile...##################
CHANGE NAME OF ANSI COMPILER HERE################CC=gcc#
Current valuesforDATABASE are: INFORMIX, DB2, TDAT (Teradata)#SQLSERVER,
SYBASE, ORACLE#
Current valuesforMACHINE are:ATT, DOS, HP, IBM, ICL, MVS,#SGI,
SUN, U2200, VMS, LINUX, WIN32#
Current valuesforWORKLOAD are:TPCHDATABASE=ORACLEMACHINE=LINUXWORKLOAD=TPCH...[oracle@redflag11012501
tmp]$ makechmod755update_release.sh./update_release.sh2130gcc-g-DDBNAME=\"dss\"-DLINUX-DORACLE-DTPCH-DRNG_TEST-D_FILE_OFFSET_BITS=64-c-o
build.o build.cвА¶gcc-g-DDBNAME=\"dss\"-DLINUX-DORACLE-DTPCH-DRNG_TEST-D_FILE_OFFSET_BITS=64-O-o
dbgen build.o driver.o bm_utils.ornd.o print.o load_stub.o bcd2.o speed_seed.o text.o permute.o rng64.o-lmgcc-g-DDBNAME=\"dss\"-DLINUX-DORACLE-DTPCH-DRNG_TEST-D_FILE_OFFSET_BITS=64-c-o
qgen.o qgen.cgcc-g-DDBNAME=\"dss\"-DLINUX-DORACLE-DTPCH-DRNG_TEST-D_FILE_OFFSET_BITS=64-c-o
varsub.o varsub.cgcc-g-DDBNAME=\"dss\"-DLINUX-DORACLE-DTPCH-DRNG_TEST-D_FILE_OFFSET_BITS=64-O-o
qgen build.o bm_utils.o qgen.ornd.o varsub.o text.o bcd2.o permute.o speed_seed.o rng64.o-lm--зЉЦиѓСеЃМжИРзЪДеПѓжЙІи°МжЦЗдїґ[oracle@redflag11012501
tmp]$ ls*gendbgenqgen
гААгААзФ®зЉЦиѓСе•љзЪДdbgenдЇІзФЯжµЛиѓХжХ∞жНЃпЉМqgenдЇІзФЯжߕ胥иѓ≠еП•гАВ
--зФЯжИР1GBзЪДжµЛиѓХжХ∞жНЃ[oracle@redflag11012501
tmp]$ ./dbgen-s1TPC-H
Population Generator (Version2.13.0)Copyright
Transaction Processing Performance Council1994-2010Doyou
wanttooverwrite ./supplier.tbl ? [Y/N]:
YDoyou
wanttooverwrite ./customer.tbl ? [Y/N]:
Y[oracle@redflag11012501
tmp]$[oracle@redflag11012501
tmp]$ ls-l*tbl-rw-r--r--1oracle
oinstall2434614401-3011:29customer.tbl-rw-r--r--1oracle
oinstall75986328701-3011:29lineitem.tbl-rw-r--r--1oracle
oinstall222401-3011:29nation.tbl-rw-r--r--1oracle
oinstall17195216101-3011:29orders.tbl-rw-r--r--1oracle
oinstall11898461601-3011:29partsupp.tbl-rw-r--r--1oracle
oinstall2413489901-3011:29part.tbl-rw-r--r--1oracle
oinstall38901-3011:29region.tbl-rw-r--r--1oracle
oinstall140918401-3011:29supplier.tbl--qgenйЬАи¶БеЬ®queriesзЫЃељХеТМdists.dssжЦЗдїґдЄ≠иѓїеПЦж®°жЭњ[oracle@redflag11012501
tmp]$ cd queries[oracle@redflag11012501
queries]$ ../qgenOpen
failedfor./dists.dss at bm_utils.c:308[oracle@redflag11012501
queries]$ cp ../dists.dss .[oracle@redflag11012501
queries]$ ../qgen--using1296360498asa
seedtothe RNGselectl_returnflag,l_linestatus,sum(l_quantity)assum_qty,sum(l_extendedprice)assum_base_price,sum(l_extendedprice*(1-l_discount))assum_disc_price,sum(l_extendedprice*(1-l_discount)*(1+l_tax))assum_charge,avg(l_quantity)asavg_qty,avg(l_extendedprice)asavg_price,avg(l_discount)asavg_disc,count(*)ascount_orderfromlineitemwherel_shipdate<=date'1998-12-01'
- interval '93' day (3)group
byl_returnflag,l_linestatusorder
byl_returnflag,l_linestatus;where
rownum<=-1;
гААгААдїОдЄКйЭҐзЪДиЊУеЗЇзїУжЮЬеПѓдї•зЬЛеЗЇпЉМиЩљзДґжМЗеЃЪдЇЖжХ∞жНЃеЇУеПВжХ∞пЉМqgenдЇІзФЯзЪДжߕ胥иѓ≠еП•дїНзДґдЄНзђ¶еРИoracleзЪДиѓ≠ж≥ХиІДеИЩгАВеП™жШѓжЈїеК†дЇЖдЄАдЄ™where rownum<=жЭ°дїґпЉМдїНзДґйЬАи¶БдЇЇеЈ•зЉЦиЊСпЉМеЬ®selectеЙНйЭҐеҐЮеК†select * from,зДґеРОеЖНе∞ЖеОЯеІЛзЪДжߕ胥дљЬдЄЇе≠Ржߕ胥зФ®()жЛђиµЈжЭ•пЉМжЬАеРОеЖНеК†дЄКwhere rownumжЭ°дїґпЉМж≥®жДПе∞Жrownum<=-1дЄ≠зЪД-1жФєдЄЇдЄАдЄ™иЊГе§ІзЪДж≠£жХіжХ∞гАВеП¶е§Ц3е§ДйЬАи¶БйТИеѓєOracleиѓ≠ж≥ХдњЃжФєзЪДеЬ∞жЦєжШѓпЉЪе∞ЖsubstringеЗљжХ∞дњЃжФєдЄЇsubstrеЗљжХ∞пЉМе∞Жи°®еИЂеРНеЙНйЭҐзЪДasеЕ≥йФЃе≠ЧеОїжОЙ,е∞Же≠Ржߕ胥жЮДжИРзЪДеИЂеРНеРОзЪДеИЧеРНзІїеК®еИ∞е≠Ржߕ胥зЪДselectе≠РеП•гАВ
гААгААжИСдїђеЬ®дњЃжФєеЃМжИРзЪДеМЕеРЂ22дЄ™жߕ胥иѓ≠еП•зЪДsqlиДЪжЬђеЙНзЂѓеТМжЬЂе∞ЊеК†дЄКе¶ВдЄЛеПВжХ∞пЉМе∞±еПѓдї•жЦєдЊњеЬ∞ињЫи°Ме§Ъжђ°жµЛиѓХгАВ
settimionlines140pages5000trimspoolontermout
offsetautot
offspool
test.logвА¶pool
offexit
гААгААе¶ВжЮЬжШѓйЬАи¶БеЉЇеИґеєґи°Мжߕ胥пЉМеИЩйЗЗзФ®дЄЛйЭҐзЪДиЃЊзљЃгАВжЧ†иЃЇеОЯеІЛи°®жШѓеР¶еЉАеРѓдЇЖеєґи°МпЉМиЃЊеЃЪдЇЖдїАдєИеєґи°МеЇ¶пЉМжߕ胥дЉШеМЦеЩ®йГљйЗЗзФ®еєґи°Мжߕ胥гАВи¶БжЯ•зЬЛеРДжߕ胥зЪДжЧґйЧіпЉМеЬ®linuxдЄЛеПѓдї•зФ®grepеСљдї§пЉЪ
settimionlines140pages5000trimspoolontermout
offalter
session force parallel query;вА¶[oracle@redflag11012602
tpch]$ cat test.log|grep"Elapsed:"Elapsed:00:01:06.24Elapsed:00:00:03.83вА¶Elapsed:00:00:19.08Elapsed:00:00:17.28Elapsed:00:00:06.06
гААгААеЬ®WindowsдЄКеПѓдї•зФ®findеСљдї§еЃМжИРеРМж†ЈзЪДдїїеК°пЉМе¶В: find "Elapsed:" test.logгАВ
гААгААдЄЙгАБжХ∞жНЃеК†иљљеТМжߕ胥жАІиГљ
гААгААжЬђжЦЗдЄНеЗЖе§ЗеЕ®йЭҐдїЛзїНOracleзЪДеЯЇжЬђеКЯиГљеТМзЙєжЬЙеКЯиГљпЉМйВ£йЬАи¶БдЄАжЬђдє¶зЪДзѓЗеєЕпЉМеЄВйЭҐдЄКдєЯжЬЙеЊИе§Ъдє¶еПѓдЊЫеПВиАГгАВињЩйЗМеП™еѓєеИЖжЮРеЮЛжХ∞жНЃе§ДзРЖзЫЄеЕ≥зЪДеКЯиГљеБЪзЃАи¶БдїЛзїНеТМиѓДжµЛгАВ
гААгААдЄЛйЭҐж≤њзФ®TPC-H scaleдЄЇ10зЪДе§ІзЇ¶10Gе≠ЧиКВжХ∞жНЃжЭ•ињЫи°МиЊГе§ІжХ∞жНЃйЗПзЪДжµЛиѓХпЉМеЕИињЫи°МжХ∞жНЃеК†иљљжµЛиѓХпЉМжµЛиѓХеЙНпЉМеЕИеИЫеїЇдЄУзФ®дЇОжµЛиѓХзЪДи°®з©ЇйЧіtpch_tsпЉМзФ±дЇОжИСдїђи¶БжµЛиѓХзЪДжХ∞жНЃйЗПе§ІзЇ¶10GBпЉМиАГиЩСеИ∞PCT_FREEеТМеЕґдїЦеЉАйФАпЉМжККи°®з©ЇйЧізЪДе§Іе∞ПеЃЪдЄЇ20GBгАВзДґеРОеИЫеїЇtpchзФ®жИЈпЉМе∞ЖtpchзФ®жИЈзЪДйїШиЃ§и°®з©ЇйЧіиЃЊдЄЇtpch_ts,еЖНеИ©зФ®tpchжЇРдї£з†БеМЕдЄ≠зЪДdss.ddlжЦЗдїґеИЫеїЇйЬАи¶БжµЛиѓХзЪД8дЄ™и°®гАВеП¶е§ЦпЉМdss.riжЦЗдїґдЄ≠еМЕеРЂдЇЖи°®зЪДдЄїйФЃеТМе§ЦйФЃзЇ¶жЭЯпЉМдЄЇдЇЖжПРйЂШжХ∞жНЃеК†иљљйАЯеЇ¶пЉМжИСдїђдЄНжЙІи°МеЃГгАВ
SQL>conn/assysdbaConnected.SQL>create
tablespace tpch_ts datafile'/user1/tpch/tpch.dbf'size 20000m nologging;Tablespace
created.Elapsed:00:01:19.53SQL>create
user tpch identified by tpch temporary tablespace temp default tablespace tpch_ts ;User
created.Elapsed:00:00:00.13SQL>grant
connect,resourcetotpch;Grant
succeeded.Elapsed:00:00:00.02SQL>grant
create any directorytotpch;Grant
succeeded.Elapsed:00:00:00.00
гААгАА1гАБsqlldrеК†иљљ
гААгААжИСдїђйЗЗзФ®OracleзЪДе§ЦйГ®жЦЗдїґеК†иљљеЈ•еЕЈsqlldrжЭ•ињЫи°МгАВ
гААгААsqlldrзЪДеК†иљљжЬЙ2зІНж®°еЉПпЉМеЄЄиІДиЈѓеЊДеТМзЫіжО•иЈѓеЊДпЉМеЙНиАЕи¶Бе∞ЖжХ∞жНЃиљђеМЦдЄЇINSERTиѓ≠еП•пЉМйАЪињЗSGAеМЇеК†иљљпЉМеРОиАЕе∞ЖжХ∞жНЃеЬ®еЖЕе≠ШдЄ≠зїДжИРжХ∞жНЃеЇУзЪДжХ∞жНЃеЭЧж†ЉеЉПпЉМзЫіжО•еЖЩеЕ•жХ∞жНЃжЦЗдїґпЉМйБњеЕНдЇЖиѓ≠еП•иІ£йЗКеТМиЃ∞ељХжЧ•ењЧзЪДеЉАйФАпЉМеЫ†ж≠§еЬ®з±їдЉЉжХ∞жНЃдїУеЇУзЪДе§ІйЗПжХ∞жНЃеѓЉеЕ•жЧґпЉМдЄАиИђйЗЗзФ®зЫіжО•иЈѓеЊДеК†иљљгАВ
гААгААsqlldrеК†иљљйЬАи¶БеЗЖе§ЗдЄАдЄ™жОІеИґжЦЗдїґпЉМжППињ∞е§ЦйГ®жЦЗдїґеТМжХ∞жНЃеЇУдЄ≠зЪДи°®зЪДеѓєеЇФеЕ≥з≥їеТМдЄАдЇЫеПВжХ∞йАЙй°єпЉМдї•lineitemи°®дЄЇдЊЛпЉЪ
----SQL*UnLoader:
Fast Oracle Text Unloader (GZIP), Release3.0.1--(@)
Copyright Lou Fangxin (AnySQL.net)2004-2010,
all rights reserved.----CREATE
TABLE lineitem (--L_ORDERKEY
NUMBER(38),--L_PARTKEY
NUMBER(38),--L_SUPPKEY
NUMBER(38),--L_LINENUMBER
NUMBER(38),--L_QUANTITY
NUMBER(15,2),--L_EXTENDEDPRICE
NUMBER(15,2),--L_DISCOUNT
NUMBER(15,2),--L_TAX
NUMBER(15,2),--L_RETURNFLAG
VARCHAR2(1),--L_LINESTATUS
VARCHAR2(1),--L_SHIPDATEDATE,--L_COMMITDATEDATE,--L_RECEIPTDATEDATE,--L_SHIPINSTRUCT
VARCHAR2(25),--L_SHIPMODE
VARCHAR2(10),--L_COMMENT
VARCHAR2(44)--);--OPTIONS(BINDSIZE=2097152,READSIZE=2097152,ERRORS=-1,ROWS=50000000)LOAD
DATAINFILE'lineitem.tbl'
"STR X'0a'"INSERT
INTO TABLE lineitemFIELDS
TERMINATED BY'|' TRAILING NULLCOLS("L_ORDERKEY"CHAR(40)
NULLIF"L_ORDERKEY"=BLANKS,"L_PARTKEY"CHAR(40)
NULLIF"L_PARTKEY"=BLANKS,"L_SUPPKEY"CHAR(40)
NULLIF"L_SUPPKEY"=BLANKS,"L_LINENUMBER"CHAR(40)
NULLIF"L_LINENUMBER"=BLANKS,"L_QUANTITY"CHAR(18)
NULLIF"L_QUANTITY"=BLANKS,"L_EXTENDEDPRICE"CHAR(18)
NULLIF"L_EXTENDEDPRICE"=BLANKS,"L_DISCOUNT"CHAR(18)
NULLIF"L_DISCOUNT"=BLANKS,"L_TAX"CHAR(18)
NULLIF"L_TAX"=BLANKS,"L_RETURNFLAG"CHAR(1)
NULLIF"L_RETURNFLAG"=BLANKS,"L_LINESTATUS"CHAR(1)
NULLIF"L_LINESTATUS"=BLANKS,"L_SHIPDATE"DATE"YYYY-MM-DD
HH24:MI:SS"NULLIF"L_SHIPDATE"=BLANKS,"L_COMMITDATE"DATE"YYYY-MM-DD
HH24:MI:SS"NULLIF"L_COMMITDATE"=BLANKS,"L_RECEIPTDATE"DATE"YYYY-MM-DD
HH24:MI:SS"NULLIF"L_RECEIPTDATE"=BLANKS,"L_SHIPINSTRUCT"CHAR(25)
NULLIF"L_SHIPINSTRUCT"=BLANKS,"L_SHIPMODE"CHAR(10)
NULLIF"L_SHIPMODE"=BLANKS,"L_COMMENT"CHAR(44)
NULLIF"L_COMMENT"=BLANKS)
гААгААжИСдїђзЬЛеИ∞пЉМжОІеИґжЦЗдїґдЄ≠иЃЊзљЃдЇЖе§ЦйГ®жЦЗдїґзЪДи°МеИЖйЪФзђ¶дЄОеИЧеИЖйЪФзђ¶пЉМROWSеПВжХ∞жШѓеЄЄиІДиЈѓеЊДзЪДзїСеЃЪжХ∞зїДи°МжХ∞пЉМжИЦзЫіжО•иЈѓеЊДжѓПжђ°дњЭе≠Ши°МжХ∞гАВеК†иљљжЦєеЉПжШѓINSERT,ж≠§е§ЦињШеПѓдї•еПЦеАЉAPPENDгАБREPLACEеТМTRUNCATEгАВи¶БжЙІи°МINSERTпЉМ ењЕй°їдњЭиѓБи°®дЄЇз©ЇпЉМеР¶еИЩsqlldrжК•йФЩпЉМдЄНиГљзїІзї≠жЙІи°МгАВе¶ВжЮЬжГ≥еРСи°®дЄ≠еҐЮеК†иЃ∞ељХпЉМеПѓдї•жМЗеЃЪеК†иљљйАЙй°єдЄЇAPPEND;дЄЇдЇЖжЫњжНҐи°®дЄ≠еЈ≤жЬЙзЪДжХ∞жНЃпЉМеПѓдї•дљњзФ®REPLACEжИЦTRUNCATEгАВREPLACEдљњзФ®DELETEиѓ≠еП•еИ†йЩ§еЕ®йГ®иЃ∞ељХ;еЫ†ж≠§пЉМе¶ВжЮЬи¶БеК†иљљзЪДи°®дЄ≠еЈ≤зїПеМЕеРЂиЃЄе§ЪиЃ∞ељХпЉМињЩдЄ™жУНдљЬжЙІи°МеЊЧеЊИжЕҐгАВTRUNCATEдљњзФ® TRUNCATE SQLеСљдї§пЉМжЙІи°МжЫіењЂпЉМеЫ†дЄЇеЃГдЄНењЕзЙ©зРЖеЬ∞еИ†йЩ§жѓПдЄАи°МгАВдљЖжШѓTRUNCATE дЄНиГљеЫЮйААгАВи¶Бе∞ПењГеЬ∞иЃЊзљЃињЩдЄ™йАЙй°єпЉМжЬЙжЧґеАЩеЕґдїЦеПВжХ∞дєЯдЉЪељ±еУНињЩдЄ™йАЙй°єгАВNULLIFжМЗеЃЪдЇЖељУе§ЦйГ®жЯРеИЧжХ∞жНЃдЄЇз©ЇжЧґзЪДе§ДзРЖжЦєеЉПгАВ
гААгААзФ±дЇОжХ∞жНЃдїУеЇУеЇФзФ®йАЪеЄЄжХ∞жНЃйЗПиЊГе§ІпЉМе∞Же§ЦйГ®жЦЗдїґеОЛзЉ©еПѓдї•еЗПе∞Се≠ШеВ®з©ЇйЧіеТМиѓїжЦЗдїґзЪДI/OпЉМеК†иљљжЧґеИ©зФ®еСљеРНзЃ°йБУе∞ЖиІ£еОЛеРОжХ∞жНЃйЗНеЃЪеРСеИ∞/user1/daaжЦЗдїґпЉМйАЪињЗеЬ®sqlldrеСљдї§и°МжМЗеЃЪdataеПВжХ∞еПѓдї•и¶ЖзЫЦжОІеИґжЦЗдїґзЪДеРМеРНеПВжХ∞гАВ
[root@redflag11012602
bin]# mkfifo/user1/daa[root@redflag11012602
bin]# chmod666/user1/daa[root@redflag11012602
bin]# su-oracle[oracle@redflag11012602
~]$ gunzip-c/user1/tpch/lineitem.tbl.gz>/user1/daa&[1]22955[oracle@redflag11012602
tpch]$date;sqlldr tpch/tpch control=lineitem_sqlldr2.ctl
data=/user1/daa direct=truelog=lineitem_sqlldr2_10.log
;date2011еєі
05жЬИ 01жЧ• жШЯжЬЯжЧ•08:34:45CSTSQL*Loader:
Release11.2.0.2.0-ProductiononSun
May108:34:452011Copyright
(c)1982,2009, Oracleand/orits
affiliates.All rights reserved.Save
data point reached-logical record count50000000.Load
completed-logical record count59986052.[1]+Donegunzip-c/user1/tpch/lineitem.tbl.gz>/user1/daa(wd:
~)(wdnow:/user1/tpch)2011еєі
05жЬИ 01жЧ• жШЯжЬЯжЧ•08:42:45CST)
гААгААзФ®жЧґ8еИЖйТЯпЉМе§ІзЇ¶1еИЖйТЯ1GBжХ∞жНЃгАВе¶ВжЮЬеРМдЄАдЄ™и°®жЬЙе§ЪдЄ™е§ЦйГ®жХ∞жНЃжЦЗдїґпЉМйВ£дєИйАЪињЗиЃЊзљЃParallelеПВжХ∞=TRUEпЉМйЗЗзФ®еєґи°МеК†иљљпЉМеПѓдї•жПРйЂШеК†иљљйАЯеЇ¶гАВж≥®жДПParallelеПВжХ∞еП™жШѓи°®з§ЇеЕБиЃЄе§ЪдЄ™sqlldrињЫз®ЛеРМжЧґеК†иљљпЉМиАМдЄНжШѓеѓєељУеЙНиѓ≠еП•йЗЗзФ®еєґи°МжЦєеЉПпЉМдєЯе∞±жШѓиѓіпЉМдЄАдЄ™sqlldrеСљдї§еП™иГљдЄ≤и°МеК†иљљгАВдЄЛйЭҐжИСдїђзФ®еєґи°МжЦєеЉПеК†иљљеРМж†ЈзЪДжХ∞жНЃпЉМжѓФиЊГеК†иљљжЧґйЧігАВ
гААгААй¶ЦеЕИпЉМе∞ЖеОЯеІЛжХ∞жНЃжЛЖеИЖжИР4дЄ™жЦЗдїґпЉМињЩйЗМжИСдїђйЗЗзФ®linuxз≥їзїЯжПРдЊЫзЪДsplitеЈ•еЕЈпЉМеЫ†дЄЇжАїи°МжХ∞е§ІзЇ¶6еНГдЄЗи°МпЉМеЫ†ж≠§иІДеЃЪеНХдЄ™жЦЗдїґи°МжХ∞1500дЄЗи°МгАВ
[root@redflag11012501
tpch2]# gzip--stdout-d/user1/app/oradata/tpch2/lineitem.tbl.gz>/user1/daa&[1]28085[root@redflag11012501
tpch2]#date;split-l15000000-d/user1/daa;date2011еєі
04жЬИ 19жЧ• жШЯжЬЯдЇМ16:09:11CST[1]+Donegzip--stdout-d/user1/app/oradata/tpch2/lineitem.tbl.gz>/user1/daa2011еєі
04жЬИ 19жЧ• жШЯжЬЯдЇМ16:10:53CST[root@redflag11012501
tpch2]# ls-l x*-rw-r--r--1root
root195103329804-1916:09x00-rw-r--r--1root
root196217422404-1916:10x01-rw-r--r--1root
root196218247804-1916:10x02-rw-r--r--1root
root196032374004-1916:10x03
гААгААе¶ВжЮЬеОЯеІЛжЦЗдїґеЈ≤зїПжЬЙе§ЪдЄ™пЉМйВ£дєИпЉМиІЖжЦЗдїґзЪДе§Іе∞ПеТМдЄ™жХ∞пЉМе¶ВжЮЬйГљжѓФиЊГеє≥еЭЗпЉМйВ£дєИдЄНйЬАи¶БеЖНеИЖеЙ≤пЉМе¶ВжЮЬе≠ШеЬ®дЄ™еИЂжЦЗдїґзЙєеИЂе§ІпЉМйВ£дєИеѓєж≠§жЦЗдїґзїІзї≠еИЖеЙ≤гАВзДґеРОпЉМеРМж†Је∞ЖжХ∞жНЃжЦЗдїґзФ®gzipеОЛзЉ©гАВ
гААгААдЄЛдЄАж≠•пЉМжИСдїђйЬАи¶БдњЃжФєжОІеИґжЦЗдїґзЪДеК†иљљжЦєеЉПдЄЇAPPEND,еєґи°МеК†иљљењЕй°їеЬ®APPENDжЦєеЉПдЄЛжЙНиГљињЫи°МпЉМеЫ†дЄЇеЕґдїЦжЦєеЉПйГљи¶Бж±Ви°®дЄЇз©ЇжИЦе∞Жи°®жЄЕз©ЇеРОжЙНиГљињЫи°МгАВ
gunzip-c/user1/tpch/x00.gz>/user1/daa&gunzip-c/user1/tpch/x01.gz>/user1/dab&gunzip-c/user1/tpch/x02.gz>/user1/dac&gunzip-c/user1/tpch/x03.gz>/user1/dad&--еЬ®еРОеП∞еєґи°МжЙІи°Мsqlldrsqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/daa
direct=trueparallel=truelog=lineitem_sqlldr_a.log&sqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dab
direct=trueparallel=truelog=lineitem_sqlldr_b.log&sqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dac
direct=trueparallel=truelog=lineitem_sqlldr_c.log&sqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dad
direct=trueparallel=truelog=lineitem_sqlldr_d.log&--еПѓдї•иІВеѓЯеИ∞еРОеП∞жЬЙ4дЄ™sqlldrињЫз®Л[oracle@redflag11012602
tpch]$ ps-ef|grep sqlldroracle23205231297708:48pts/700:00:34sqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/daa
direct=trueparallel=truelog=lineitem_sqlldr_a.logoracle23206231297708:48pts/700:00:33sqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dab
direct=trueparallel=truelog=lineitem_sqlldr_b.logoracle23209231297608:48pts/700:00:33sqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dac
direct=trueparallel=truelog=lineitem_sqlldr_c.logoracle23210231297608:48pts/700:00:33sqlldr
tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dad
direct=trueparallel=truelog=lineitem_sqlldr_d.logoracle2322723129008:49pts/700:00:00grep
sqlldr--4дЄ™sqlldrињЫз®ЛеЗ†дєОеРМжЧґзїУжЭЯ[oracle@redflag11012602
tpch]$Load
completed-logical record count15000000.Load
completed-logical record count15000000.Load
completed-logical record count15000000.Load
completed-logical record count14986052.--жЯ•зЬЛжѓПдЄ™sqlldrдїїеК°зЪДжЧ•ењЧ[oracle@redflag11012602
tpch]$ tail lineitem_sqlldr_a.logTotal
logical records rejected:0Total
logical records discarded:0Total
stream buffers loaded by SQL*Loader main thread:3709Total
stream buffers loaded by SQL*Loader load thread:5565Run
beganonSun May0108:48:202011Run
endedonSun May0108:50:302011Elapsedtimewas:00:02:10.32CPUtimewas:00:01:36.34[oracle@redflag11012602
tpch]$ tail lineitem_sqlldr_b.logTotal
logical records rejected:0Total
logical records discarded:0Total
stream buffers loaded by SQL*Loader main thread:3729Total
stream buffers loaded by SQL*Loader load thread:5593Run
beganonSun May0108:48:202011Run
endedonSun May0108:50:302011Elapsedtimewas:00:02:10.29CPUtimewas:00:01:36.92[oracle@redflag11012602
tpch]$ tail lineitem_sqlldr_c.logTotal
logical records rejected:0Total
logical records discarded:0Total
stream buffers loaded by SQL*Loader main thread:3730Total
stream buffers loaded by SQL*Loader load thread:5593Run
beganonSun May0108:48:202011Run
endedonSun May0108:50:302011Elapsedtimewas:00:02:10.28CPUtimewas:00:01:36.76[oracle@redflag11012602
tpch]$ tail lineitem_sqlldr_d.logTotal
logical records rejected:0Total
logical records discarded:0Total
stream buffers loaded by SQL*Loader main thread:3728Total
stream buffers loaded by SQL*Loader load thread:5591Run
beganonSun May0108:48:202011Run
endedonSun May0108:50:302011Elapsedtimewas:00:02:10.28CPUtimewas:00:01:36.19
гААгААжХ∞жНЃйЗЗзФ®еєґи°МеК†иљљеРОпЉМжЧґйЧіе§ІеєЕеЇ¶еЗПе∞СпЉМе§ІзЇ¶жШѓеОЯжЭ•зЪДеЫЫеИЖдєЛдЄАгАВWindowsжУНдљЬз≥їзїЯдЄНжФѓжМБ&иѓ≠ж≥ХзЪДеРОеП∞ињЫз®ЛпЉМеПѓдї•зФ®жЙУеЉАе§ЪдЄ™cmdз™ЧеП£пЉМеИЖеИЂжЙІи°Ме§ЪдЄ™дЄНеРМзЪДsqlldrиѓ≠еП•зЪДжЦєеЉПпЉМдєЯиГљиЊЊеИ∞зЫЄеРМзЪДжХИжЮЬгАВйЬАи¶БжМЗеЗЇзЪДжШѓпЉМжЬНеК°еЩ®зЪДI/OиГљеКЫеѓєеК†иљљжЬЙеЈ®е§ІзЪДељ±еУНпЉМе¶ВжЮЬиѓїеЖЩзЪДI/OеЄ¶еЃљеЈ≤зїПзФ®жї°пЉМйВ£дєИеЃЮйЩЕдЄКе∞±жШѓsqlldrеЬ®з≠ЙеЊЕI/OеЃМжИРпЉМйВ£дєИж≠§еИїеЖНеРѓеК®е§ЪдЄ™sqlldrдєЯдЄНдЉЪжПРйЂШеК†иљљжАІиГљгАВ
гААгАА2гАБе§ЦйГ®и°®жЦєеЉПеК†иљљ
гААгААе§ЦйГ®и°®жФѓжМБsqlldrеЉХжУОеТМжХ∞жНЃж≥µпЉМзФ±дЇОжИСдїђзЪДжХ∞жНЃжШѓжЦЗжЬђжЦєеЉПпЉМжХЕйЗЗзФ®sqlldrеЉХжУОгАВ
гААгААй¶ЦеЕИеИЫеїЇе§ЦйГ®и°®пЉМж≥®жДПtypeдЄЇoracle_loaderпЉМPREPROCESSORйАЙжЛ©zcat,и°®з§ЇзФ®zcatзЪДзїУжЮЬжПТеЕ•гАВ
SQL>create
directory tpch_diras'/user1/tpch';Directory
created.Elapsed:00:00:00.02SQL>create
directory zcat_diras'/bin';Directory
created.CREATE
TABLE lineitem_ext (L_ORDERKEYNUMBER(10),
L_PARTKEY NUMBER(10),
L_SUPPKEY NUMBER(10),
L_LINENUMBERNUMBER(38),
L_QUANTITY NUMBER,
L_EXTENDEDPRICE NUMBER,
L_DISCOUNT NUMBER,
L_TAXNUMBER,
L_RETURNFLAGCHAR(1),
L_LINESTATUS CHAR(1),
L_SHIPDATEVARCHAR2(10),
L_COMMITDATE VARCHAR2(10),
L_RECEIPTDATEVARCHAR2(10),
L_SHIPINSTRUCTVARCHAR2(25),
L_SHIPMODE VARCHAR2(10),
L_COMMENT VARCHAR2(44))ORGANIZATION
EXTERNAL (TYPE
oracle_loaderDEFAULT
DIRECTORY tpch_dirACCESS
PARAMETERS (
RECORDS DELIMITED BY NEWLINE
PREPROCESSOR zcat_dir:'zcat'
BADFILE'bad_%a_%p.bad'
LOGFILE'log_%a_%p.log'
FIELDS TERMINATED BY'|'
MISSING FIELD VALUES ARENULL)LOCATION
('lineitem.tbl.gz'))PARALLEL2REJECT
LIMIT0/Table
created.Elapsed:00:00:00.03
гААгААзДґеРОзФ®зЫіжО•иЈѓеЊДе∞Же§ЦйГ®и°®жХ∞жНЃжПТеЕ•еЃЮйЩЕи¶Бе§ДзРЖзЪДи°®гАВзФ±дЇОжЧ•жЬЯеИЧйЬАи¶БжМЗеЃЪж†ЉеЉПпЉМзФ®to_dateеПВжХ∞е§ДзРЖгАВ
insert/*+append*/into
h_lineitemselectL_ORDERKEY,
L_PARTKEY,
L_SUPPKEY,
L_LINENUMBER,
L_QUANTITY,
L_EXTENDEDPRICE,
L_DISCOUNT,
L_TAX,
L_RETURNFLAG,
L_LINESTATUS,
to_date(L_SHIPDATE,'YYYY-MM-DD'),
to_date(L_COMMITDATE,'YYYY-MM-DD'),
to_date(L_RECEIPTDATE,'YYYY-MM-DD'),
L_SHIPINSTRUCT,L_SHIPMODE,
L_COMMENTfrom
lineitem_ext;/59986052rows
created.Elapsed:00:10:26.35--еИ©зФ®е§ЪдЄ™жЦЗдїґеИЫеїЇеП¶дЄАдЄ™е§ЦйГ®и°®пЉМеП™дњЃжФєlocationCREATE
TABLE lineitem_ext2 (L_ORDERKEYNUMBER(10),вА¶LOCATION
('x00.gz','x01.gz','x02.gz','x03.gz'))вА¶--зФ®зђђдЇМдЄ™е§ЦйГ®и°®еєґи°МжПТеЕ•insert/*+append
parallel (a8)*/into lineitemaselect/*+parallel
(b8)*/L_ORDERKEY,
L_PARTKEY,
L_SUPPKEY,
L_LINENUMBER,
L_QUANTITY,
L_EXTENDEDPRICE,
L_DISCOUNT,
L_TAX,
L_RETURNFLAG,
L_LINESTATUS,
to_date(L_SHIPDATE,'YYYY-MM-DD'),
to_date(L_COMMITDATE,'YYYY-MM-DD'),
to_date(L_RECEIPTDATE,'YYYY-MM-DD'),
L_SHIPINSTRUCT,
L_SHIPMODE,
L_COMMENTfrom
lineitem_ext2 b;/59986052rows
created.Elapsed:00:04:13.94--зФ®зђђдЄАдЄ™е§ЦйГ®и°®еєґи°МжПТеЕ•insert/*+append
parallel (a8)*/into lineitemaselect/*+parallel
(b8)*/L_ORDERKEY,вА¶from
lineitem_ext b;/59986052rows
created.Elapsed:00:08:59.89
гААгААжИСдїђзЬЛеИ∞пЉМlocationеНХдЄ™е§ЦйГ®жЦЗдїґзЪДе§ЦйГ®и°®пЉМжМЗеЃЪдЇЖеєґи°МжПТеЕ•дїНзДґйЬАи¶Бе§ІзЇ¶9еИЖйТЯжЧґйЧіпЉМжѓФsqlldrеНХињЫз®ЛињШжЕҐпЉМйЗЗзФ®е§ЪдЄ™е§ЦйГ®жЦЗдїґзЪДе§ЦйГ®и°®,еєґи°МжПТеЕ•жЧґйЧі4еИЖйТЯе§ЪпЉМдєЯжѓФsqlldrеєґи°МеК†иљљеЈЃеЊИе§ЪпЉМto_dateзЪДжЧ•жЬЯиљђжНҐжШѓжЬЙдЇЫељ±еУНпЉМдљЖзФ±дЇОеК†иљљеЉХжУОеЃЮйЩЕж≤°жЬЙеМЇеИЂпЉМдєЯе∞±йЪЊдї•иґЕињЗsqlldrеСљдї§зЪДжХИжЮЬгАВ
гААгАА3гАБжХ∞жНЃжߕ胥
гААгААдЄЇдЇЖжѓФиЊГдЄНеРМжЭ°дїґдЄЛзЪДжߕ胥зїУжЮЬпЉМжИСдїђињЫи°МдЇЖ4зІНзїДеРИзЪДжߕ胥гАВеИЖеИЂжШѓпЉЪеНХињЫз®ЛдЄНеОЛзЉ©пЉМеєґи°МдЄНеОЛзЉ©пЉМеНХињЫз®ЛеОЛзЉ©пЉМеєґи°МеОЛзЉ©пЉМжѓПзІНжµЛиѓХеБЪ2йБНпЉМеПЦиЊГењЂзЪДдЄАйБНзЪДзїУжЮЬгАВ
--зФ®жЭ•еОЛзЉ©и°®зЪДиѓ≠еП•пЉМеєґи°МеПВжХ∞еПѓеК†ењЂйАЯеЇ¶пЉМдљЖеєґдЄНжФєеПШ襀moveзЪДи°®зЪДеєґи°МеЇ¶alter
table CUSTOMER move compress parallel32;alter
table LINEITEM move compress parallel32;alter
table NATION move compress parallel32;alter
table ORDERS move compress parallel32;alter
table PART move compress parallel32;alter
table PARTSUPP move compress parallel32;alter
table REGION move compress parallel32;alter
table SUPPLIER move compress parallel32;--еОЛзЉ©еЙНе≠ЧиКВжХ∞SQL>setnumw20SQL>selectsegment_name,sum(bytes)
from user_segments where segment_namenotlike'%EXT%' group by segment_name order by 1;SEGMENT_NAME
SUM(BYTES)--------------------------------------CUSTOMER281804800LINEITEM7730102272NATION65536ORDERS1874067456PART278986752PARTSUPP1367867392REGION65536SUPPLIER16646144--еОЛзЉ©еРОSEGMENT_NAMESUM(BYTES)---------------------------------------CUSTOMER248643584LINEITEM5389484032NATION65536ORDERS1566310400PART207290368PARTSUPP1251344384REGION65536SUPPLIER17301504
гААгААдїОдЄКйЭҐи°®зЪДеН†зФ®з©ЇйЧіеПѓиІБпЉМеѓєдЇОtpc-hжХ∞жНЃпЉМеЫ†дЄЇdbgenзФЯжИРзЪДжХ∞жНЃжѓФиЊГйЪПжЬЇпЉМеПИжШѓзђ¶еРИзђђ3иМГеЉПзЪДпЉМеЖЧдљЩиЊГе∞СпЉМOracleеОЛзЉ©зЪДжХИжЮЬдЄН姙жШОжШЊгАВиКВзЇ¶зЪДI/OжЬЙйЩР,еГПSUPPLIERи°®е§Іе∞ПеПНиАМеҐЮеК†дЇЖпЉМињШеҐЮеК†дЇЖиІ£еОЛзЪДиіЯжЛЕгАВ
гААгААдЄЛйЭҐжШѓеРДзїДжߕ胥жµЛиѓХзїУжЮЬпЉЪ
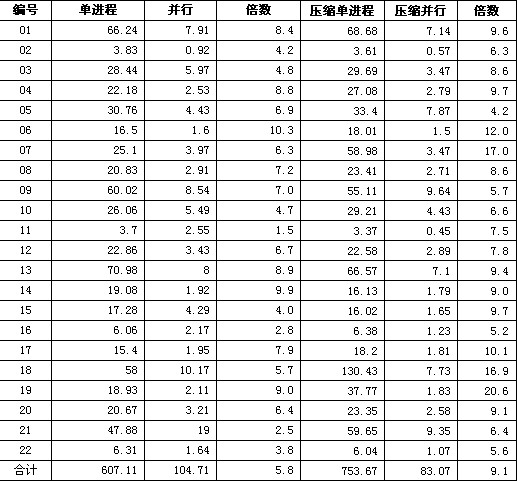
вЦ≤и°®1 TPC-H cale=10жЬ™еОЛзЉ©еТМеОЛзЉ©жХ∞жНЃзЪДжµЛиѓХеѓєжѓФпЉМеНХдљНпЉЪзІТ
гААгААеПѓиІБжЧ†иЃЇжШѓеР¶еОЛзЉ©пЉМеєґи°Мжߕ胥жѓФеНХињЫз®ЛйГљжЬЙеЗ†еАНжИЦеНБеЗ†еАНзЪДжПРйЂШпЉМеЕЈдљУжПРйЂШзЪДеАНжХ∞еТМжߕ胥зЪДз±їеЮЛеТМжЬЇеЩ®зЪДCPUдЄ™жХ∞жЬЙеЕ≥гАВзФ®жЭ•жµЛиѓХзЪДжЬЇеЩ®жЬЙ8дЄ™йАїиЊСCPU,еЬ®дЄНеОЛзЉ©зЪДжГЕеЖµдЄЛиГљжПРйЂШе§ІзЇ¶5еАНпЉМеЬ®еОЛзЉ©зЪДжГЕеЖµдЄЛпЉМеНХињЫз®ЛзЪДжАІиГљжѓФдЄНеОЛзЉ©жЫіеЈЃпЉМжЙАдї•еЕЙзЬЛжПРйЂШзЪДеАНжХ∞жШѓдЄНе§ЯзЪДпЉМињШи¶БзЬЛжߕ胥зЪДеЃЮйЩЕжЧґйЧіжѓФгАВ
гААгААдїОдЄКињ∞жХ∞жНЃжИСдїђињШеПѓдї•еЊЧеЗЇеНХињЫз®ЛеТМеєґи°МеИЖеИЂжߕ胥еОЛзЉ©еТМйЭЮеОЛзЉ©жХ∞жНЃзЪДеЈЃеЉВпЉЪ
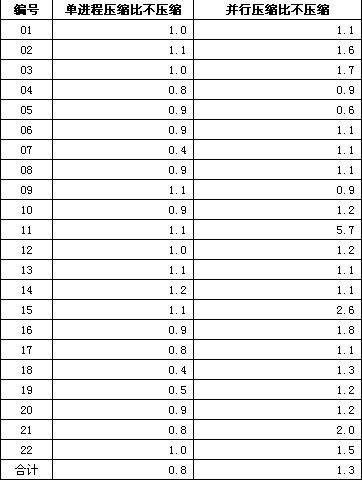
вЦ≤и°®2 TPC-H scale=10еОЛзЉ©еЙНеРОжХ∞жНЃзЪДжµЛиѓХеѓєжѓФпЉМеНХдљНпЉЪеАН
гААгААе¶ВдЄКи°®жЙАз§ЇпЉМдїОеРИиЃ°жЧґйЧізЬЛпЉМеНХињЫз®ЛеОЛзЉ©жѓФдЄНеОЛзЉ©еПНиАМйАЯеЇ¶йЩНдљОдЇЖ20%пЉМиАМеєґи°МжЭ°дїґдЄЛпЉМеИЩжЬЙ30%зЪДжАІиГљжПРйЂШгАВдїОеНХдЄ™жߕ胥зЬЛпЉМеОЛзЉ©еТМдЄНеОЛзЉ©дЇТжЬЙиГЬиіЯпЉМињЩиЈЯеЙНйЭҐжИСдїђеИЧеЗЇзЪДеОЛзЉ©жЦЗдїґе§Іе∞ПжЬЙеЕ≥пЉМе¶ВжЮЬI/Oж≤°жЬЙеПШеМЦжИЦиАЕжЫіе§ІпЉМйВ£дєИеК†дЄКиІ£еОЛеЉАйФАпЉМжߕ胥йАЯеЇ¶дЄЛйЩНдєЯжШѓењЕзДґзЪДгАВ
гААгААеЫЫгАБжАІиГљи∞ГжХіеТМдЉШеМЦ
гААгААOracleжАІиГљи∞ГжХіеТМдЉШеМЦжШѓдЄ™е§НжЭВзЪДеСљйҐШпЉМжґµзЫЦи°®зїУжЮДиЃЊиЃ°гАБжߕ胥职聰гАБеПВжХ∞и∞ГжХіз≠ЙжЦєйЭҐпЉМеЙНжЦЗдїЛзїНзЪДеОЛзЉ©еТМеєґи°МйГљжШѓзЃАеНХзЪДеПВжХ∞и∞ГжХідЉШеМЦжЙЛжЃµпЉМе¶ВжЮЬжШѓеЃЮйЩЕзЪДжߕ胥пЉМиАМдЄНжШѓеЯЇеЗЖжµЛиѓХпЉМжИСдїђе∞±йЬАи¶БеЕЕеИЖеИ©зФ®OracleзЪДеКЯиГљпЉМйТИеѓєжѓПдЄ™жߕ胥еНХзЛђдЉШеМЦгАВ
гААгАА1гАБжߕ胥зЪДжФєеЖЩ
гААгААзФ±дЇОOracleзЪДжߕ胥дЉШеМЦеЩ®зЫЄеѓєжѓФиЊГжЩЇиГљпЉМеѓєSQLиѓ≠еП•дє¶еЖЩзЪДи¶Бж±ВжѓФеЕґдїЦжХ∞жНЃеЇУи¶БзЫЄеѓєдљОдЄАдЇЫпЉМињЩзїЩеЇФзФ®еЉАеПСдЇЇеСШеЄ¶жЭ•дЇЖжЦєдЊњгАВжѓФе¶Взђђ15дЄ™жߕ胥пЉМдЄЛйЭҐ2зІНеЃМеЕ®ињ•еЉВзЪДеЖЩж≥ХпЉМжЙІи°МжХИжЮЬеНіжШѓеЈЃдЄНе§ЪзЪДгАВ
--ж†єжНЃеОЯеІЛзЪДзђђ15дЄ™жߕ胥иѓ≠еП•пЉМе∞ЖиІЖеЫЊжФєдЄЇе≠Ржߕ胥SQL>select*from(2select3
s_suppkey,4
s_name,5
s_address,6
s_phone,7
total_revenue8from9
supplier,10
(11select12
l_suppkey supplier_no,13
sum(l_extendedprice*(1-l_discount))total_revenue14
from15
lineitem16
where17
l_shipdate>=date'1995-02-01'18andl_shipdate<date'1995-02-01'
+ interval '3' month19
group by20
l_suppkey21
)22
revenue023where24
s_suppkey=supplier_no25andtotal_revenue=(26select27
max(total_revenue)28
from29
(30select31
l_suppkey supplier_no,32
sum(l_extendedprice*(1-l_discount))total_revenue33
from34
lineitem35
where36
l_shipdate>=date'1995-02-01'37andl_shipdate<date'1995-02-01'
+ interval '3' month38
group by39
l_suppkey40
)41
revenue042
)43order
by44
s_suppkey)45where
rownum<=10;S_SUPPKEY
S_NAMES_ADDRESS S_PHONE TOTAL_REVENUE----------------------------------------------------------------------------83966Supplier#0000839660ITp9HCIUHEHgWCjeTt24-897-113-54922147201.69еЈ≤зФ®жЧґйЧі:00:00:20.46--дњЃжФєеРОзЪДзђђ15дЄ™жߕ胥иѓ≠еП•пЉМеИЖжЮРеЗљжХ∞еЖЩж≥ХSQL>selects_suppkey,
s_name, s_address, s_phone, total_revenue2fromsupplier3
,(selectl_suppkeyassupplier_no,4sum(l_extendedprice*(1-l_discount))astotal_revenue5
,RANK() OVER(ORDER BY sum(l_extendedprice*(1-l_discount))
DESC)ASrnk6
from lineitem7where
l_shipdate>=date'1995-02-01'8andl_shipdate<date'1995-02-01'
+ interval '3' month9
group by10l_suppkey11)
revenue112where
s_suppkey=supplier_no13ANDrnk=114order
by s_suppkey;S_SUPPKEY
S_NAMES_ADDRESS S_PHONE TOTAL_REVENUE----------------------------------------------------------------------------83966Supplier#0000839660ITp9HCIUHEHgWCjeTt24-897-113-54922147201.69еЈ≤зФ®жЧґйЧі:00:00:20.16
гААгАА2гАБзїЯиЃ°дњ°жБѓжФґйЫЖеТМзЃ°зРЖ
гААгААж≠£з°ЃзЪДзїЯиЃ°дњ°жБѓеѓєOracleеЊЧеЗЇиЊГе•љзЪДжЙІи°МиЃ°еИТжЬЙеНБеИЖйЗНи¶БзЪДељ±еУНпЉМеЬ®е§ІйЗПжПТеЕ•жИЦжЫіжЦ∞жХ∞жНЃдї•еРОпЉМзФЪиЗ≥еѓєи°®ињЫи°МmoveеРОпЉМйЬАи¶БйЗНжЦ∞жФґйЫЖзїЯиЃ°дњ°жБѓгАВжѓФе¶ВпЉЪеѓєжЯРдЄ™зФ®жИЈдЄЛжЙАжЬЙзЪДеѓєи±°жФґйЫЖзїЯиЃ°дњ°жБѓпЉМdegreeи°®з§Їеєґи°МжФґйЫЖзЪДеєґи°МеЇ¶гАВ
SQL>settimionSQL>exec
dbms_stats.gather_schema_stats('TPCH');PL/SQL
procedure successfully completed.Elapsed:00:19:29.98SQL>exec
dbms_stats.gather_schema_stats(ownname=>'TPCH', degree=> 32)PL/SQL
procedure successfully completed.Elapsed:00:14:55.46
гААгААOracleдєЯжПРдЊЫдЇЖиЗ™еК®зїЯиЃ°дњ°жБѓжФґйЫЖдїїеК°пЉМдЄАиИђеЬ®жЩЪйЧіжЙІи°МпЉМиѓ•ињЗз®Лй¶ЦеЕИж£АжµЛзїЯиЃ°дњ°жБѓзЉЇе§±еТМйЩИжЧІзЪДеѓєи±°гАВзДґеРОз°ЃеЃЪдЉШеЕИзЇІпЉМеЖНеЉАеІЛињЫи°МзїЯиЃ°дњ°жБѓгАВ
гААгААињЩдЄ™еКЯиГљињШжШѓеЊИжЬЙзФ®зЪДпЉМжѓФе¶Взђђ18дЄ™жߕ胥пЉМеНХињЫз®Лжߕ胥пЉМж≤°жЬЙжФґйЫЖзїЯиЃ°дњ°жБѓеЙНйЬАи¶Б2дЄ™е§Ъе∞ПжЧґпЉМиЗ™еК®зїЯиЃ°дњ°жБѓжФґйЫЖеРОеП™и¶БдЄНеИ∞2еИЖйТЯе∞±еЃМжИРдЇЖгАВе¶ВжЮЬдЄНеИ©зФ®зїЯиЃ°дњ°жБѓпЉМйВ£дєИењЕй°їи¶Бж±ВеЉАеПСдЇЇеСШйЭЮеЄЄзЖЯжВЙOracleзЪДеРДзІНињЮжО•еТМжОТеЇПжЦєж≥ХпЉМдЇЇеЈ•жЈїеК†жПРз§ЇжЭ•ељ±еУНжЙІи°МиЃ°еИТпЉМињЩж≤°жЬЙзЫЄељУдЄ∞еѓМзЪДеЉАеПСзїПй™МжШѓеБЪдЄНеИ∞зЪДгАВ
гААгААињШжЬЙеЕґдїЦзЪДдЉШеМЦжЙЛжЃµпЉМжѓФе¶ВжЈїеК†ењЕи¶БзЪД糥еЉХпЉМзФ±дЇОжЧґйЧіжЙАйЩРпЉМеЕЉдєЛеЙНжЦЗжЙАињ∞зЪДвАЬTPC-Hж£АжЯ•еПѓзФ®жХ∞жНЃзЪДе§Іе§ЪжХ∞вАЭеОЯеЫ†пЉМж≤°жЬЙињЫи°МжµЛиѓХгАВдљЖеНХдїОжЈїеК†dss.riдЄ≠зЪДдЄїе§ЦйФЃзЇ¶жЭЯжЭ•зЬЛпЉМжµЛиѓХзїУжЮЬеТМдЄНеЄ¶дЄїе§ЦйФЃзЇ¶жЭЯпЉМеЈЃеИЂдЄНе§ІпЉМеЕЈдљУжХ∞жНЃе∞±дЄНжШУеЈ≤еИЧеЗЇдЇЖпЉМжЬЙеЕіиґ£зЪДиѓїиАЕеПѓдї•иЗ™и°Мж£Ай™МгАВ
гААгААдЇФгАБе∞ПзїУ
гААгААзЬЛеИ∞ињЩйЗМпЉМзЫЄдњ°иѓїиАЕеѓєOracleжХ∞жНЃеЇУеЈ≤зїПжЬЙдЇЖеИЭж≠•зЪДеН∞и±°пЉМеЃЙи£ЕиЩљзДґжѓФиЊГе§НжЭВпЉМеЃЙи£ЕеМЕдєЯдљУзІѓеЇЮе§ІпЉМдљЖеКЯиГљињШжШѓеЊИеЉЇе§ІпЉМжАІиГљдєЯжѓФиЊГе•љпЉМиГљеЕЕеИЖеИ©зФ®з°ђдїґиµДжЇРгАВеѓєеЉАеПСдЇЇеСШжЭ•иѓіпЉМдЄНењЕеЬ®SQLзЪДиѓ≠ж≥ХдЄКйݥ姙ињЗйТїз†ФпЉМиљђиАМдїОдЄЪеК°зРЖиІ£дЄКйЭҐжМЙйАЪеЄЄзЪДеЖЩж≥Хе∞±иГљеПЦеЊЧиЊГе•љзЪДжХИжЮЬпЉМеПѓдї•е§Іе§ІжПРйЂШдїЦдїђзЪДеЈ•дљЬжХИзОЗгАВOracle 11gињШжПРдЊЫдЇЖеКЯиГљжЫіеЉЇзЪДSQLи∞ГдЉШеЈ•еЕЈпЉМеПѓдї•еЄЃеК©еЉАеПСдЇЇеСШжФєеЦДдїЦдїђзЪДSQLгАВ
гААгААи¶Биѓіе≠ШеЬ®зЪДйЧЃйҐШпЉМ Oracleеѓєз°ђдїґзЪДи¶Бж±ВиЊГйЂШпЉМйЬАи¶БжПРдЊЫиЊГе§ІзЪДеЖЕе≠ШеТМз£БзЫШз©ЇйЧіпЉМдєЯйЬАи¶Бе§ЪдЄ™CPUгАВеЕґжђ°пЉМеОЛзЉ©зОЗдЄНйЂШпЉМеОЛзЉ©жХ∞жНЃеѓєеНХињЫз®Лжߕ胥жЬЙеЃ≥жЧ†зЫКпЉМдљЖеѓєдЇОдЉБдЄЪеЇФзФ®пЉМе§ІеЃєйЗПе≠ШеВ®еТМе§ЪCPUйГљдЄНжШѓе§ІйЧЃйҐШпЉМеЫ†ж≠§ињЩдЄ™зЉЇзВєељ±еУНдЄНе§ІгАВеЖНе∞±жШѓOracleз≥їзїЯзЪДе§НжЭВжАІпЉМжѓФе¶ВеРМж†ЈжШѓзїЯиЃ°дњ°жБѓжФґйЫЖпЉМе¶ВжЮЬзФ®зЪДеПВжХ∞дЄНеРМпЉМдЇІзФЯзЪДжЙІи°МиЃ°еИТдєЯжЬЙе§©е£§дєЛеИЂпЉМеѓєжХ∞жНЃеЇУзЃ°зРЖдЇЇеСШзЪДи¶Бж±ВињШжШѓиЊГйЂШзЪДгАВ
гААгААжАїзЪДжЭ•иѓіпЉМе¶ВжЮЬзФ®жИЈеНБеИЖеЬ®жДПжߕ胥жАІиГљпЉМеѓєжХ∞жНЃеОЛзЉ©и¶Бж±ВдЄАиИђпЉМйВ£дєИOracleжШѓдЄАдЄ™е•љзЪДйАЙжЛ©гАВиАМеѓєжЬАзїИзФ®жИЈжЭ•иѓіпЉМжЬђжЦЗж≤°жЬЙжПРеПКзЪДеی嚥еМЦзЪДзЃ°зРЖеЈ•еЕЈEMдєЯжШѓдЄАдЄ™еЊИе•љзЪДеЈ•еЕЈпЉМдЄНењЕжЙЛеЈ•иЊУеЕ•еТМиЃ∞ењЖе§ІйЗПзЪДзЃ°зРЖSQLиѓ≠еП•пЉМе∞±иГљзЫСжОІжХ∞жНЃеЇУињРи°МеТМињЫи°МжЧ•еЄЄзїіжК§еЈ•дљЬгАВ


- 2011-12-27 15:28
- жµПиІИ 1074
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
и°МеЉПжХ∞жНЃеЇУиѓДжµЛпЉЪOracle 11g R2дЉБдЄЪзЙИ
гАКжЮДеїЇжЬАйЂШеПѓзФ®OracleжХ∞жНЃеЇУз≥їзїЯпЉЪOracle 11gR2 RACзЃ°зРЖгАБзїіжК§дЄОжАІиГљдЉШеМЦгАЛдїОз°ђдїґеТМиљѓдїґдЄ§дЄ™зїіеЇ¶з≥їзїЯдЄФеЕ®йЭҐеЬ∞иЃ≤иІ£дЇЖOracle 11g R2 RACзЪДжЮґжЮДгАБеЈ•дљЬеОЯзРЖгАБзЃ°зРЖеПКзїіжК§зЪДз≥їзїЯзРЖиЃЇеТМжЦєж≥ХпЉМдї•еПКжАІиГљдЉШеМЦзЪДжКАеЈІеТМжЬАдљ≥еЃЮиЈµ...
иµДжЇРеРНзІ∞пЉЪдЄіеН±дЄНжГІпЉЪOracle 11gжХ∞жНЃеЇУжБҐе§НжКАжЬѓеЖЕеЃєзЃАдїЛпЉЪгАКдЄіеН±дЄНжГІ:Oracle 11gжХ∞жНЃеЇУжБҐе§НжКАжЬѓгАЛеИЖдЄЇдЄЙе§ІйГ®еИЖпЉЪжБҐе§НзЪДеОЯзРЖгАБжБҐе§НзЪДеЈ•еЕЈгАБжБҐе§НзЪДеЕЈдљУж≠•й™§дЄОеЃЮжИШгАВзђђдЄАйГ®еИЖиГље§ЯиЃ©иѓїиАЕйҐЖзХ•жБҐе§НжУНдљЬзЪДжЬђиі®пЉМжШѓеЕґдїЦйГ®еИЖ...
еЃШжЦєиµДжЦЩпЉЪOracle 11g R2еНЗзЇІжЬАдљ≥еЃЮиЈµ иѓ¶зїЖдїЛзїНеНЗзЇІиГљеЄ¶жЭ•дїАдєИзЫКе§Д?жЦ∞зЙИжЬђеѓєеЇФзФ®иљѓдїґжШѓеР¶еЕЉеЃє?еНЗзЇІеРОжШѓеР¶дЉЪеѓЉиЗіеЇФзФ®жАІиГљдЄЛйЩН?йЬАи¶Беѓєз≥їзїЯињРзїіеЈ•дљЬињЫи°МеУ™дЇЫи∞ГжХі?дЄЗдЄАеНЗ篲姱賕пЉМжАОдєИеКЮ?
Redhat Enterprise 5.4пЉМDBпЉЪOracle 11g R2 X64 еЃЙи£ЕжЦЗж°£гАВ
гАКжИРеКЯдєЛиЈѓ:Oracle 11gе≠¶дє†зђФиЃ∞гАЛдЄУдЄЇеЉАеПСдЇЇеСШзЉЦеЖЩпЉМеЕИеЉХеѓЉеЉАеПСжЦ∞жЙЛзЖЯжВЙOracleзОѓеҐГпЉМзДґеРОињЫеЕ•жХ∞жНЃеЇУеЉАеПСпЉМеєґи¶БжОМжП°й°єзЫЃеЉАеПСдЄ≠зЪДдЄАдЇЫжКАеЈІгАВеЉАеПСжКАеЈІе±Хз§ЇжШѓгАКжИРеКЯдєЛиЈѓ:Oracle 11gе≠¶дє†зђФиЃ∞гАЛзЪДдЄАе§ІзЙєиЙ≤(ињЩдЄАзВєеЊИеАЉеЊЧ...
жУНдљЬз≥їзїЯпЉЪдЄ≠ж†ЗйЇТйЇЯ V6.5 жХ∞жНЃеЇУпЉЪoracle 11G R2 OracleжХ∞жНЃзЪДеЃЙи£ЕйЬАи¶БзФ®еИ∞иЊГе§ЪзЪДдЊЭиµЦеМЕпЉМеЬ®еЃЙи£ЕжУНдљЬз≥їзїЯжЧґпЉМйАЪињЗеЃЪеИґеЃЙи£Е
иµДжЇРеРНзІ∞пЉЪOracle 11g R2 DBAжУНдљЬжМЗеНЧеЖЕеЃєзЃАдїЛпЉЪOracleжХ∞жНЃеЇУжШѓдЄАжђЊдЉШзІАдЄФеЇФзФ®еєњж≥ЫзЪДеЕ≥з≥їжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯгАВжЬђдє¶еЕ®йЭҐгАБиѓ¶зїЖеЬ∞иЃ≤иІ£дЇЖOracle llgR2жХ∞жНЃеЇУзЃ°зРЖжКАжЬѓпЉМжШѓе≠¶дє†0racleжХ∞жНЃеЇУзЃ°зРЖзЪДеЃЮзФ®жХЩжЭРеТМеПВиАГдє¶гАВгААжЬђдє¶еЕ±...
oracleжХ∞жНЃеЇУпЉМ64дљНжУНдљЬз≥їзїЯпЉМеЃЙи£ЕжѓФиЊГзЃАеНХпЉМжЬђдЇЇзФµиДСдЄКе∞±жШѓзФ®зЪДињЩдЄ™
дЄіеН±дЄНжГІ ORACLE 11GжХ∞жНЃеЇУжБҐе§НжКАжЬѓ (еЃМжХізЙИ).pdf
жЮДеїЇжЬАйЂШеПѓзФ®oracleжХ∞жНЃеЇУз≥їзїЯпЉЪoracle 11gr2 racзЃ°зРЖгАБзїіжК§дЄОжАІиГљдЉШеМЦ(еИШзВ≥жЮЧ)
Oracle 11g еЃШжЦєдЄ≠жЦЗжЦЗж°£ еМЕжЛђдЄАдЄЛйГ®еИЖжЦЗж°£пЉЪ Oracle 11gпЉЪORACLE ACTIVE DATA GUARD.pdf Oracle Database 11g йЂШеПѓзФ®жАІ.pdf Oracle жХ∞жНЃеЇУ 11g пЉЪзЬЯж≠£еЇФзФ®жµЛиѓХдЄОеПѓ...йАВзФ®дЇОOracleжХ∞жНЃеЇУ11gзЪДOracleеПШжЫізЃ°зРЖеМЕ.pdf
иµДжЇРеРНзІ∞пЉЪжЮДеїЇжЬАйЂШеПѓзФ®OracleжХ∞жНЃеЇУз≥їзїЯеЖЕеЃєзЃАдїЛпЉЪгАКжЮДеїЇжЬАйЂШеПѓзФ®OracleжХ∞жНЃеЇУз≥їзїЯ(Oracle11gR2RACзЃ°зРЖзїіжК§дЄОжАІиГљдЉШеМЦ)гАЛзФ±еИШзВ≥жЮЧиСЧпЉМдїОз°ђдїґеТМиљѓдїґдЄ§дЄ™зїіеЇ¶з≥їзїЯдЄФеЕ®йЭҐеЬ∞иЃ≤иІ£дЇЖOracle11g R2RACзЪДжЮґжЮДгАБеЈ•дљЬеОЯзРЖгАБ...
иµДжЇРеРНзІ∞пЉЪOracleжХ∞жНЃеЇУзЃ°зРЖиЙЇжЬѓпЉЪ11gжЦ∞зЙєжАІиµДжЇРжИ™еЫЊпЉЪ иµДжЇР姙姲пЉМдЉ†зЩЊеЇ¶зљСзЫШдЇЖпЉМйУЊжО•еЬ®йЩДдїґдЄ≠пЉМжЬЙйЬАи¶БзЪДеРМе≠¶иЗ™еПЦгАВ
иґЕиѓ¶зїЖзЪДOracle 11g R2еЃЙи£Едї•еПКеИЫеїЇжХ∞жНЃеЇУжЦЗж°£пЉМеЙНжЃµжЧґйЧіеЉАеПСйЬАи¶БиЗ™еЈ±дЇ≤иЗ™и∞ГиѓХеЃЙи£ЕпЉМзїЭеѓєе•љзФ®пЉБ
жЮДеїЇжЬАйЂШеПѓзФ®OracleжХ∞жНЃеЇУз≥їзїЯ Oracle 11gR2 RACзЃ°зРЖгАБзїіжК§дЄОжАІиГљдЉШеМЦ.part1.rar
Oracle 11g еЃШжЦєдЄ≠жЦЗжЦЗж°£йЫЖиРГ(еЃМжХіжЙУеМЕ) еМЕжЛђпЉЪ Oracle 11gпЉЪORACLE ACTIVE DATA GUARD.pdf Oracle Database 11g йЂШеПѓзФ®жАІ.pdf Oracle жХ∞жНЃеЇУ 11g пЉЪзЬЯж≠£еЇФзФ®жµЛиѓХдЄО...йАВзФ®дЇОOracleжХ∞жНЃеЇУ11gзЪДOracleеПШжЫізЃ°зРЖеМЕ.pdf
oracle11g_R2еЃЙи£ЕжЙЛеЖМ.
linuxдЄЛoracle 11g R2 dataguard
еЃШжЦєиµДжЦЩпЉЪOracle 11gжХ∞жНЃеЇУжЦ∞зЙєжАІдЄОеНЗзЇІжЬАдљ≥еЃЮиЈµ иѓ¶зїЖдїЛзїНOracle11gжЦ∞зЙєжАІпЉЪвАУ еИЖеМЇгАБвАУ Active DGгАБвАУ йЧ™еЫЮгАБвАУ RACгАБвАУ еЃЙеЕ®гАБвАУ еОЛзЉ©гАБвАУ RATгАБвАУ OEM 12cгАБвАУ еЕґеЃГпЉЪвАҐ 11gеНЗзЇІжЬАдљ≥еЃЮиЈµгАБвАУ еНЗзЇІиЈѓеЊДгАБвАУ жЬАињС...